How to Scrape Interactive Geospatial Data
Translations:
With few exceptions, everything that appears in your browser can be downloaded and transformed into useable data formats, with many organisations or individuals maintain complex and publicly accessible datasets containing valuable information. Despite being publicly viewable, in many cases the underlying data is not able to be downloaded and further analysed. This guide will focus on how to scrape geospatial data which is explorable, but which cannot be exported for personal analysis, along with introducing some of the concepts surrounding databases which are stored on public servers and accessible through an application programming interface (API).
The guide will focus on downloading geospatial data, but hopefully some of these concepts will also be applicable to other formats of data which is stored in a similar fashion.
Why Scrape Geospatial Data?
You may want to do this for several reasons, the foremost of which is subjecting the data to further analysis.
- Further Analysis
An interactive map of razed neighbourhoods in Kurdish-majority provinces of Turkey may allow you to see the extent and location of cleared areas; however, by scraping and downloading the data, it is possible to analyse it much more rigorously, such as in relation to census data or remotely-sensed data on improvised barriers installed prior to clearing.
You could also find an interactive map of the Separation Barrier between Israel and the West Bank. By downloading the data, you can explore it in relation to the 1948 Green Line, and create a map showing areas ‘annexed’ by Israel, between the separation barrier and Green Line, or analysing locations of security incidents by their distance to the barrier.
- Geolocating Footage
Additionally, scraping can be useful for geolocating footage. If you are analysing a video from Libya where high-voltage power lines cross over a highway, it would be possible to find an interactive map of Libya’s energy infrastructure, and do further GIS analysis to isolate locations where these power lines cross a highway.
- Archiving Data
Beyond analytical purposes, it can also be important to scrape these interactive maps for the purposes of archiving them. When looking for examples to scrape for this article, I tried to find two particular interactive maps, one showing early, non-violent protest events in Syria before the civil war started, and another by Caerus Group showing the location and group control of checkpoints in the city of Aleppo in 2013. Both of these maps were no longer being maintained and could not be accessed, therefore this informative and potentially important data has largely been lost.
What You Will Need
- Google Chrome (Google’s Chrome browser contains a few useful tools for isolating the useful packets of information, and with limited amounts of data transformation, they can be translated into common file-types, such as CSV-files.)
- Notepad++ (or any other program that lets you use Regular Expression (RegEx) search tools)
- Excel, Google’s equivalent “Sheets”, or another spreadsheet program
- Optional, for visualisation, is a mapping program (ArcMap [paid software], QGIS or Google Earth Pro)
It is important to note that data architecture is extremely varied, and the preparation needed to present the data differs with almost every dataset. There is no single method to do this, but all the necessary programs have extremely robust online support to guide you through everything specific you will need to do (this is important because RegEx can be a huge pain).
Guide
What follows is a step-by-step guide of how to acquire data that is not publicly downloadable. It will be done by using three different datasets, starting with easy map data to download (crisis data in Iraq by ACLED), to more complex data (attacks on Syrian health-care facilities by Physicians for Human Rights, and The Aleppo Project by the Central European University).
ACLED Data
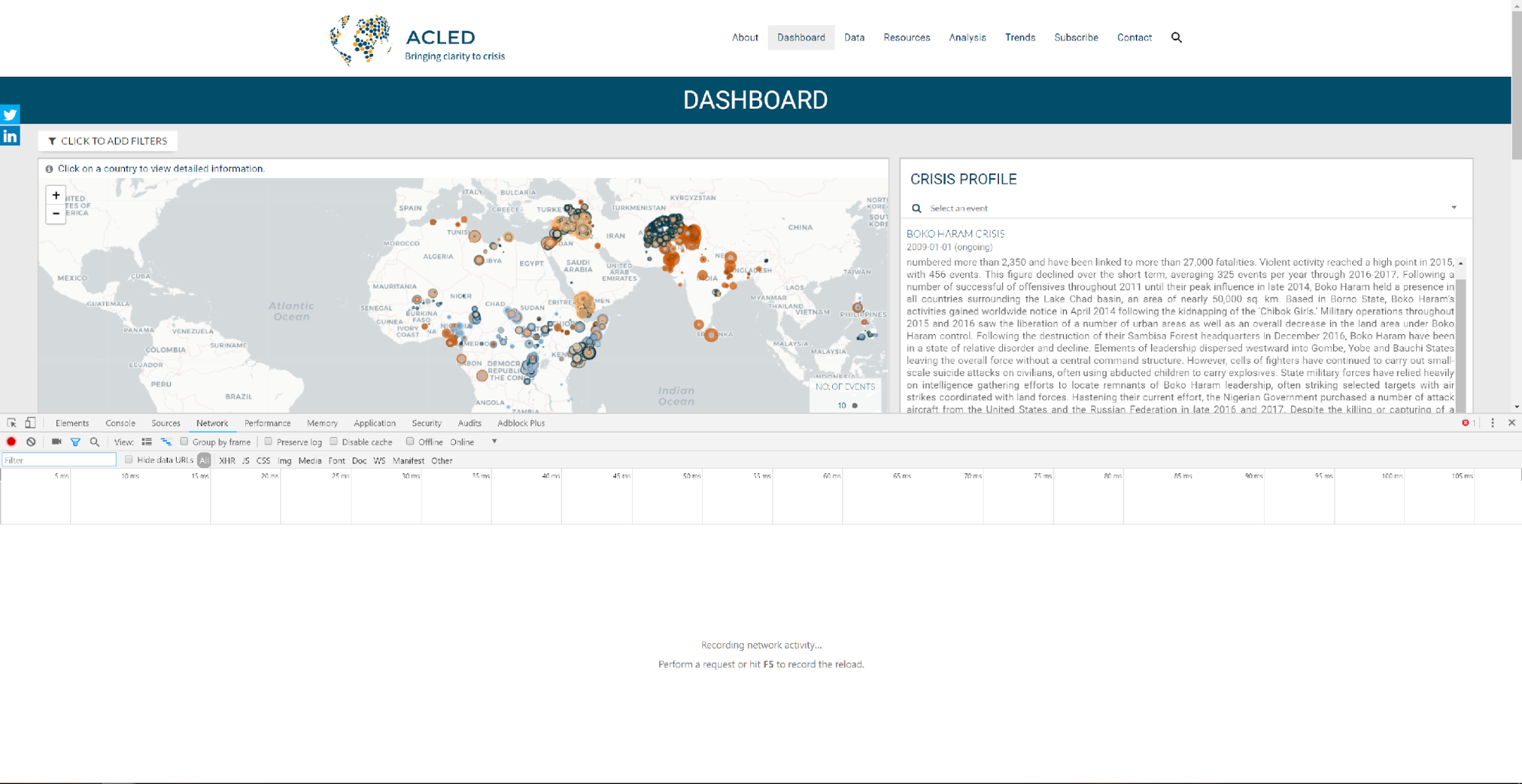
A good introductory dataset is the ACLED Dashboard. Although this data is also publicly accessible, it is a useful learning tool showing how little the data needs to be processed.
The first step is a right click anywhere on the page and select “Inspect”, or press Ctrl+Shift+i (on PC).
Then, secondly, once the dialogue box has appeared, navigate to the “Network” tab. It should appear something like this.
Downloading Data
Navigate to Iraq on the above map; if you zoom in and move the map around you should see numbered PNG image files cascade onto the Network table – these are tiles of the base-map. The network tab basically shows you every file or script which gets initiated or downloaded by the website as you are browsing. Hidden in the code of the website are scripts which initiate further downloads. You can see these scripts in the ‘Initiator’ row in the Network tab table; for example, the base-map PNG image files are initiated by “leaflet.js:5”, which tells Carto which files you want to view.
Click on Iraq to load just the Iraq events. You will see a file which starts with “read.csv” appear – this is the data you want, and the URL it links you to is:
Let’s unpick what this link gives.
First, it links us to the ACLED API, and it allows you to query the online database to download relevant data. Each specific API should have a user guide to see exactly what can be done with it; however, ACLED is unlike most datasets in having its own API. Most datasets will be a single database or table hosted by an third-party API, but let’s focus on the easy ACLED dataset for now. If you just navigate to “https://api.acleddata.com/acled/read.csv”, it will automatically download a CSV file of the latest 500 events entered into the ACLED database, which can be viewed in Excel or another spreadsheet program.
The URL after the “read.csv” is telling the API what you want. The “limit=0’’ indicates that the query will return all matching data — you can make this any number to download the number of rows you want. The next option is limiting the search to a single country. This can be changed to any country or have other qualifiers added on; for example, if you inserted “&event_type=Riots/Protests” between “Iraq” and “&fields” you would only download Protest or Riots events. You can do similar things for actors or locations, for example…
…will result in only downloading events coded as occurring in Mosul.
The URL after “&fields=” tells the API which columns to include. This is what is important, as it is more relevant to databases without their own dedicated API. In this %7C is text encoded | character, separating the different columns. In this case, you will get iso, actor1, actor2, event_date, event_type, and so on. If there are unneeded columns, you can remove them from the URL to make the data simpler. In this case, as the API documentation is available, you can also add in fields such as %7Ccountry%7Cnotes to get more information.
At this point, as a test, try to work out what events you will download if you go to this URL:
Then download the CSV and check if the file is what you thought. You should have a CSV file with all the important columns, including latitude and longitude which can be used to import the file into Google Earth Pro or any GIS program.
Attacks on Syrian Health-Care Facilities
Now let’s try a more difficult dataset.
Physicians for Human Rights maintains an interactive map of attacks on health-care facilities in Syria. It is a detailed map, and by clicking on an event you can see a lot more information about every event. All this data is downloadable, with a bit of scraping.
- Let’s get to Inspect > Network again.
- Refresh the page to scrape up all the data that appears when you load the page. This list is a more complex. Now you have to poke around a bit to find the right item. Generally, you can search for JOSN, CSV, or SQL and one of them will have the data that you want, but in this case the only hit is for ‘SQL”, which is all about loading the Tiled Map Server Basemap.
Sometimes it is a matter of guessing and checking the files and prompting the page to load more detail relevant to what you’re looking for. In this case I found the data by clicking on an attack and prompting the browser to load more data about that event. That made a new SQL item appear, titled, in my case:
sql?q=select%20%22area%22%2C%22area_of_control%22%2C%22attack_description%22%2C%22city%22%2C%22date%22%2C%22date_stamp%22%2C%22deaths%22%2C%22exact_location%22%2C%22facility_type%22%2C%22field_61%22%2C%22field_source1%22%2C%22field_source2%22%2C%22governorate%22%2C%22hospital_name%22%2C%22hospital_type%22%2C%22image1_caption%22%2C%22image1_link%22%2C%22image1_source_caption%22%2C%22image1_source_link%22%2C%22image2%22%2C%22image2_caption%22%2C%22image2_link%22%2C%22image2_source_caption%22%2C%22image2_source_link%22%2C%22injuries%22%2C%22latitude%22%2C%22longitude%22%2C%22mode_of_attack%22%2C%22no_dead%22%2C%22no_injured%22%2C%22outcome_for_facility%22%2C%22perpetrator%22%2C%22source1_caption%22%2C%22source1_link%22%2C%22source1_period%22%2C%22source2_caption%22%2C%22source2_link%22%2C%22source2_period%22%2C%22source3_caption%22%2C%22source3_link%22%2C%22source3_period%22%2C%22source_type%22%2C%22total_no_of_attacks%22%2C%22video1%22%2C%22video1_caption%22%2C%22video1_code%22%2C%22video2%22%2C%22video2_caption%22%2C%22video2_code%22%2C%22video2_link%22%2C%22video3%22%2C%22video3_caption%22%2C%22video3_code%22%2C%22video3_link%22%2C%22video4%22%2C%22video4_caption%22%2C%22video4_code%22%2C%22video4_link%22%2C%22video_footage%22%2C%22video_height%22%2C%22weapons_used%22%20from%20(select%20*%20from%20facilityattacks_2017_12_update)%20as%20_cartodbjs_alias%20where%20cartodb_id%20%3D%20287
Opening this in a new tab shows you that this links you to the data of a single entry in the SQL database. Here, %20 represents a space, %22 is a quotation mark and %2C is a comma. From the URL we can see that this API first lists fields to show, and then selects from the entire database with “where cartodb_id = 20287” at the end limiting the search to a single entry.
We can remove this, and remove superfluous fields by adjusting the URL, for my purposes I’ve used the URL:
It is important to note that because we don’t do not have access to the databases’ user guide, it is impossible to add additional fields which may have been in the original SQL file without guessing.
Parsing the Data
When we go to that URL, instead of downloading a file, it all appears as text in the browser, this is where we need to prepare the data.
Open up Notepad++ and paste the whole text into a new file. First, we need to examine how the data is put together, and how we want it to end up in Excel or another spreadsheet program. Because this data has a lengthy description field, along with a date field, which include commas we cannot prepare it as a traditional CSV file.
So the way I want to prepare this file is to have it as a table, where each line has rows separated by a | character. To get there, I want to remove the data label which appears before every entry such as “hospital_name”:, enter that into a header, and separate every value with a |.
Preparing the Data
The first step is to separate each entry into its own line, from looking at the data you can see that each entry ends with } (a curly brace),. This is where we use Regular Expression. It is a bit complicated to get around, but thankfully you can Google basically anything you want to do and someone will have written up the code already.
Press Ctrl+H (on a PC) to open up the replace dialogue; for ease here, I will describe my replace functions in this article like “find|replace”.
Separate it into new lines by entering “\},\{|\n” in Regex. Essentially this finds all curly brace symbols, { or }, and replaces them with a new line; the \ character indicates that you are looking for that character and not using it as a function, and \n creates a new line. Now, we can clip off the superfluous coding at the start and the end, and we will see that there are a total of 492 lines, each making up one entry.
We want to separate every row with a | character, and remove the individual row labels. We can achieve that if we replace all the text between quotation marks and followed by a semi-colon. Therefore, we replace “,”(.*?)”:|,”, here, with (.*?) indicating any number of characters which fall after a ,” and before a “:.
Before we do this though, we have to think of how we are to separate the fields afterwards. Most fields would be separated with ““,””, but not digits and null/true/false values. If you go back to the browser and look the bottom of the data, you will see a list of rows and their type (string, Boolean and number), Boolean and Number are not surrounded by quotation marks which will make it harder to separate them.
So we should wrap them all in quotation marks. Again, this is easiest done with Find and Replace, firstly with the digits, enter “”:(\d.*?),| “:”\1”,”. This replaces all digits in brackets and proceeding “: characters with the digits themselves wrapped in quotation marks. All the other commands are generally simple such as “true|”true”” or “null|”null””.
Now, it’s time to remove the row labels for each entry, which we can do by using that same formula as above, “,”(.*?)”:|,” and, finally, separate all the rows with “”,”|”|””. Lastly, we try “”area”:|” to remove the first row label.
By this point it should look something like this:

One final step before we are ready to enter the data into excel. We should go back to our browser, find the URL and select the row headers:
area%22%2C%22area_of_control%22%2C%22attack_description%22%2C%22city%22%2C%22date%22%2C%22deaths%22%2C%22exact_location%22%2C%22facility_type%22%2C%22hospital_name%22%2C%22hospital_type%22%2C%22injuries%22%2C%22latitude%22%2C%22longitude%22%2C%22mode_of_attack%22%2C%22no_dead%22%2C%22no_injured%22%2C%22outcome_for_facility%22%2C%22perpetrator%22%2C%22total_no_of_attacks%22%2C%22weapons_used
Copy and paste that into a line at the top of your Notepad++ file, and replace the encoded characters with | characters, such as “%22%2C%22||”
Entry into Excel
It’s time for Excel, or another spreadsheet program, to double check that everything is prepared right. Copy the whole document and paste it into a new excel worksheet, then, in Excel, go to the data tab and select “Text to Columns”. Choose Delineated, check the “Other” box and enter |. Then press Finish. When you go back to the worksheet make sure that there are no columns with misaligned rows. It should look even all the way down, for example:
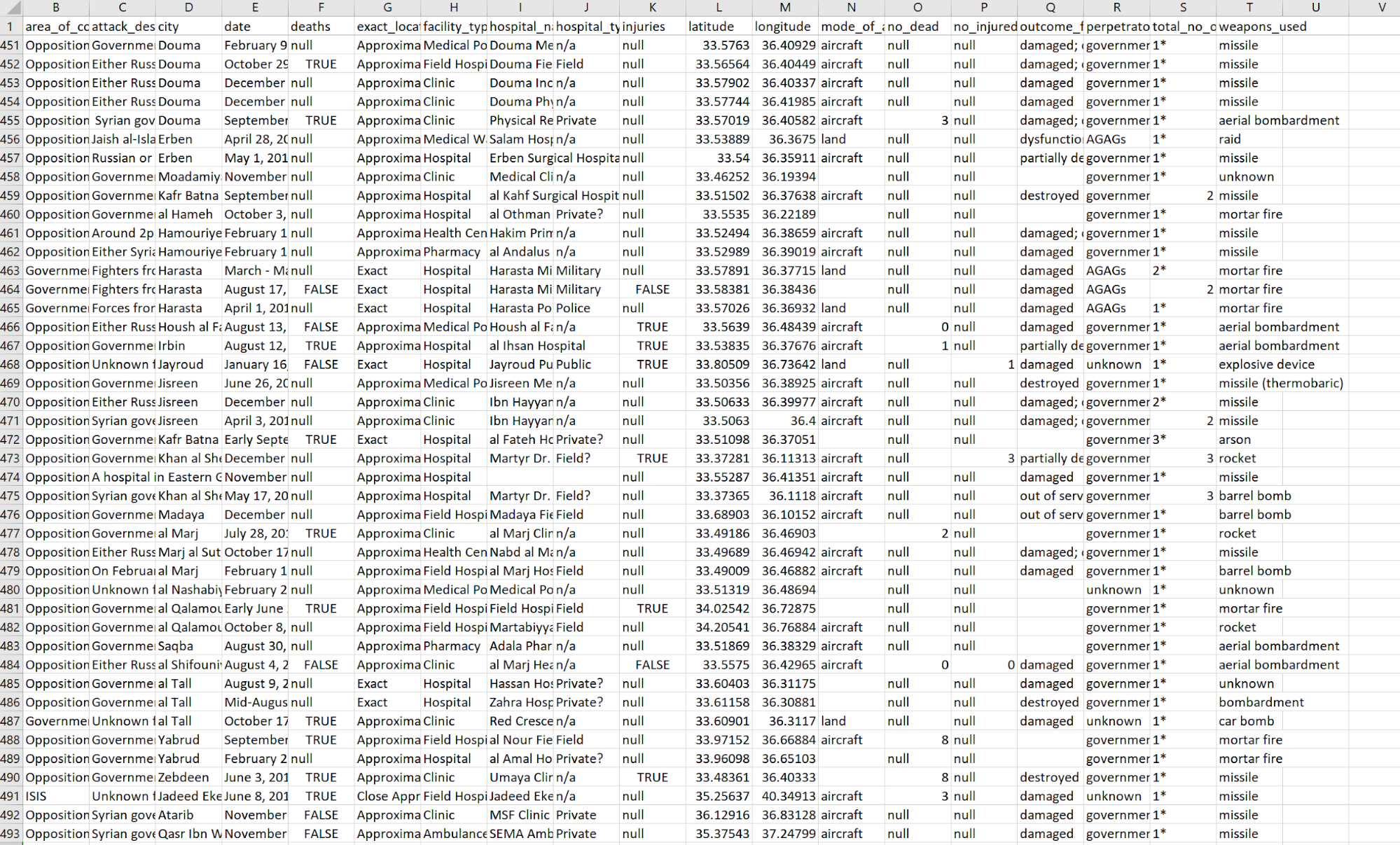
Now we have entirely scraped the data, and can analyse it however we want. The first thing I will do is replace all the Nulls with relevant entries (False in rows F and K, 0 in rows O and P).
Exploring the Data
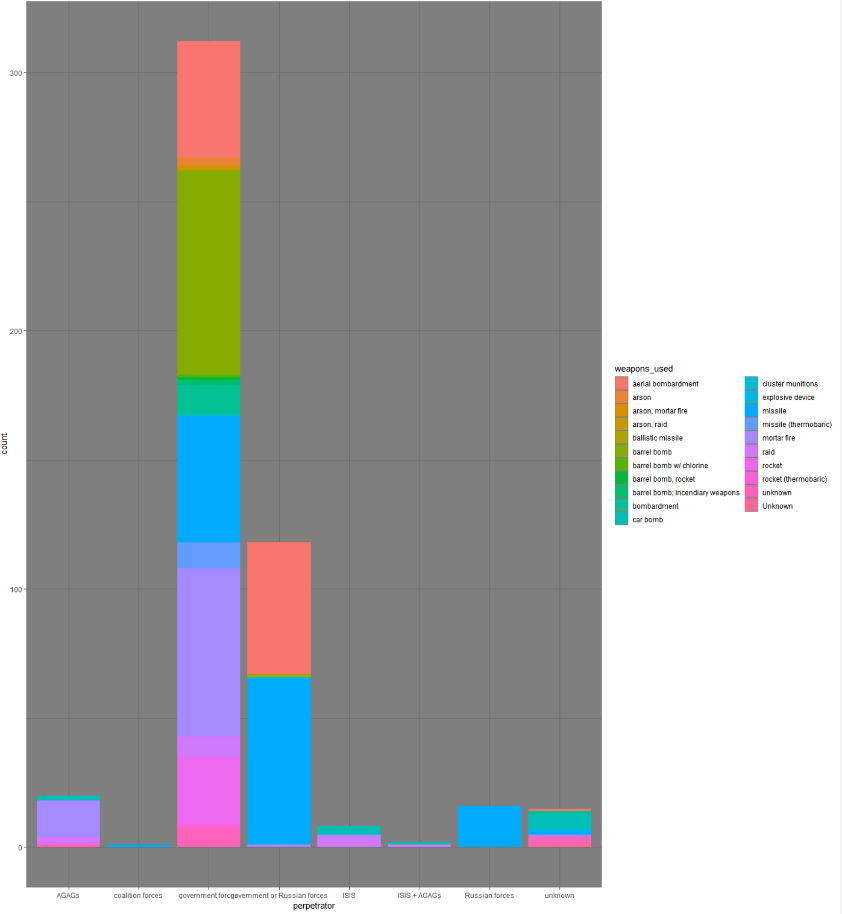
The first thing I want to do with this data is graph the most dangerous weapons used to attack health facilities, so I will insert a new row with the total number of casualties. From here we can make a pivot table that shows that Car Bombs are by far the deadliest weapon.
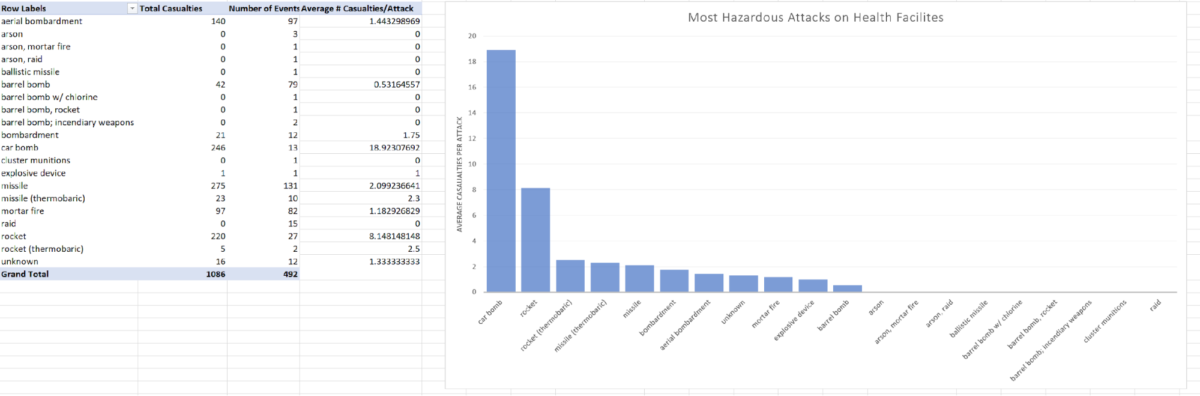
We can also see that the majority of car bombs against health facilities are not clearly attributed to any actor, but of the attributions, they are most common amongst ISIS (in this dataset AGAG means Anti-Government Armed Group).
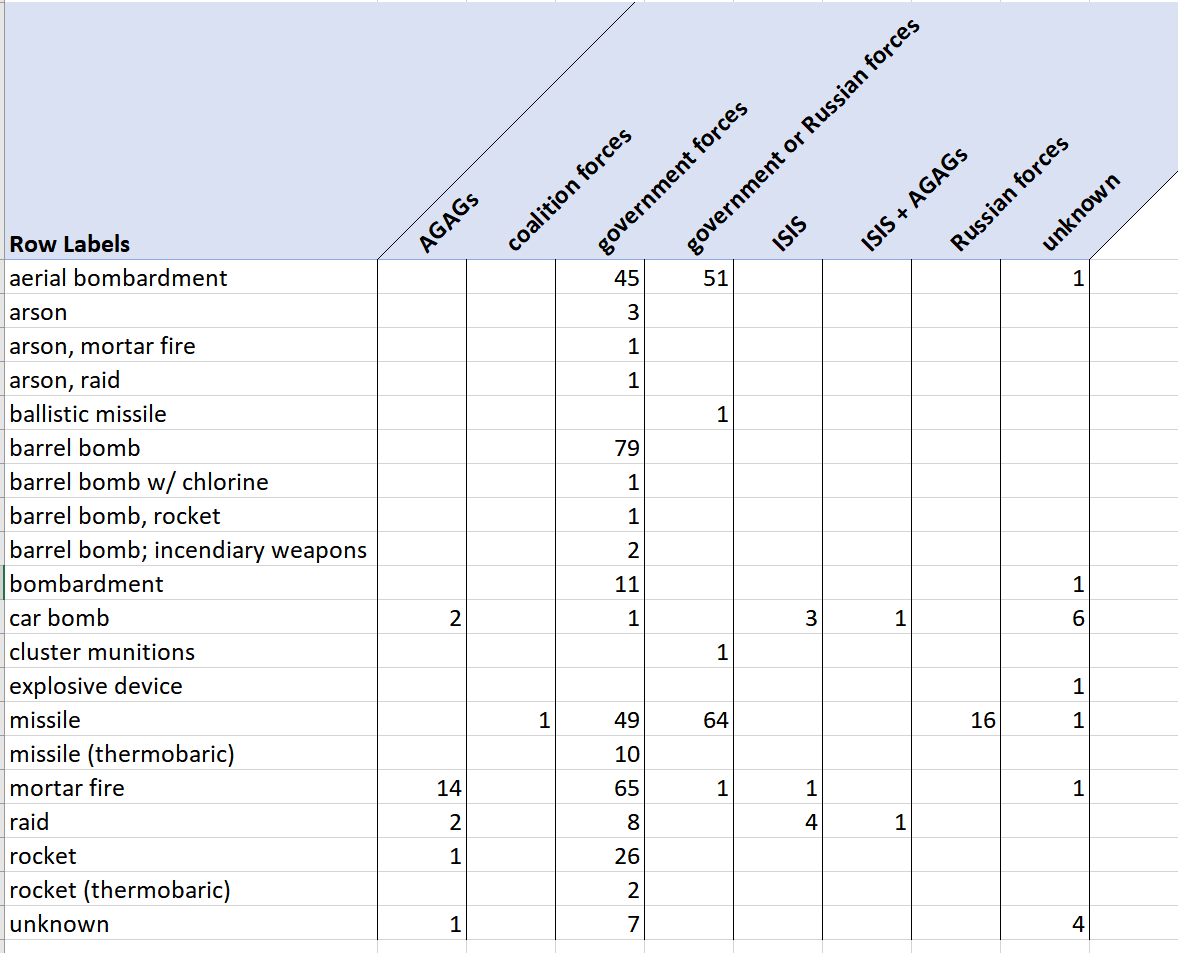
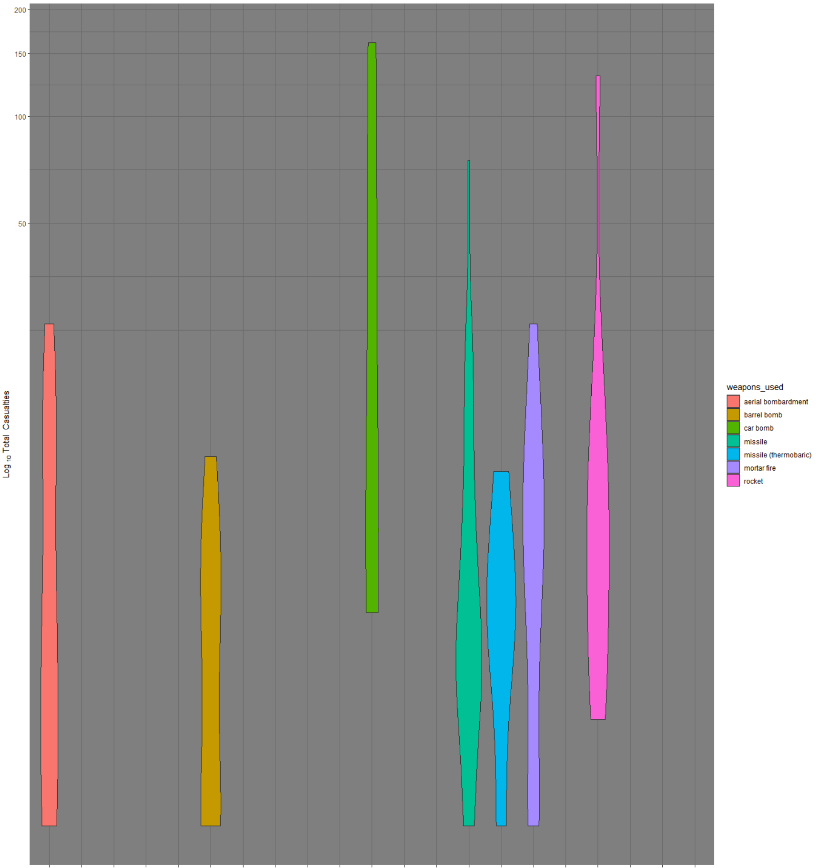
We can also import this data into any program that we would like. For example, I would like to explore violin plots of different methods and their lethality; for this, I can import the data into R Studio. In R, there is much more freedom to make different kinds of graphs to summarise the data:
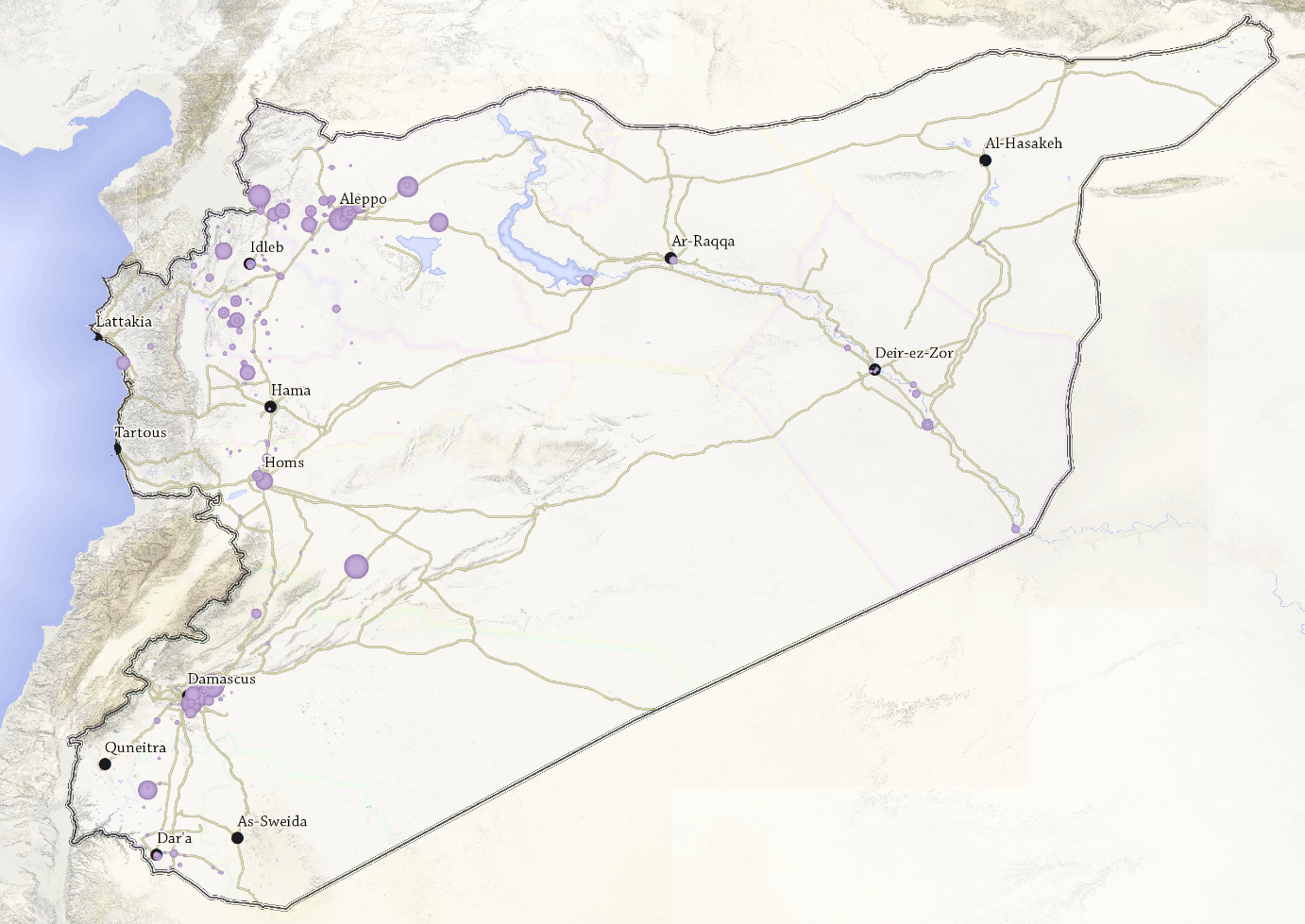
Because this is geospatial data, it is also possible to use the latitude and longitude fields to import the data into mapping programs, either Google Earth Pro, or a GIS program like ArcMap.
Extracting Polygon Features (Aleppo Neighbourhoods)
Finally, let’s take a look at some more complex geospatial features. Here we’re talking about Polygons, rather than points. This can be useful if your research needs to interact directly with territorial control, or you want to extract certain features. In this case, we’ll be looking at a detailed map of localities in Aleppo. It was curated by Aleppo Project and is linked here.
To see the neighbourhoods you have to check on the visibility of the layer. The geographic data in this dataset should be easy to find by now (look for an entry mentioning JSON and an access token), but if you’re having trouble it is here. Looking at the data you will see immediately that it is similar to the previous data for strikes against health facilities, but it has far more coordinates.
Well-Known Text
Before we get into preparing this data, the fact that we are looking at more complex geographic shapes means we also need to become familiar with Well Known Text (WKT) geographic data, this is a way of storing vector shapes (shapes defined geographically by the coordinates of their vertices) in a text format similar to traditional XML coding. Numerous programs have the ability to import this data, but it is most easily accessible and the native language of the Google Earth Engine. If you draw any polygon in Google Earth, save it as a KML and open that in Notepad, you will see a polygon in WKT.
Preparing the Data
Again, the first thing we need to do is to use Regex to separate each feature into a new line. I also used this opportunity to clear some annoying data from the front of each entry, so I used “\{“type”:”Feature”,”properties”:\{|”. We also only need the name and the coordinates for each file here, in this case. In some choropleth maps you will want to extract features as well, but for now let’s keep it simpler. You can also trim off a lot of the other fields, for example, by using “”,”NAME_A”:”(.*?)”,”title”:”(.*?)”,”description”:”(.*?)”,”marker-color”:””,”marker-size”:””,”marker-symbol”:””,”stroke”:”#000000″,”stroke-width”:1,”stroke-opacity”:1,”fill”:”#6c6c6c”,”fill-opacity”:0.20000000298023224\},”geometry”:\{|”, and “\],”type”:”Polygon”\},”id”:”(.*?)”\},|” among others. I structure my data at this point so each feature now gets 3 lines, the first for its name, the second for its coordinates, and the third as a line break to separate the entries:

The next thing we need to do is to reformat those coordinates into the same system Google Earth uses. Well Known Text formats its coordinates like “long,lat,elev long,lat,elev long,lat,elev” and so on, where long is longitude, lat is latitude and elev is elevation. This is an easy fix with the data like this, you just replace “\],\[|,0 “. Then, remove the opening square brackets, and replace the closing square brackets with “,0”.
Formating it as a KML file
Then you are done preparing the data, and it is time to place it within a KML file. Take the random KML polygon you created before, open it back up in notepad, and replace whatever is in the <name> tags with the first line, along with the contents of the <coordinates> tags.
From here all that needs to be done is to replace the coordinates and save it as a KML.
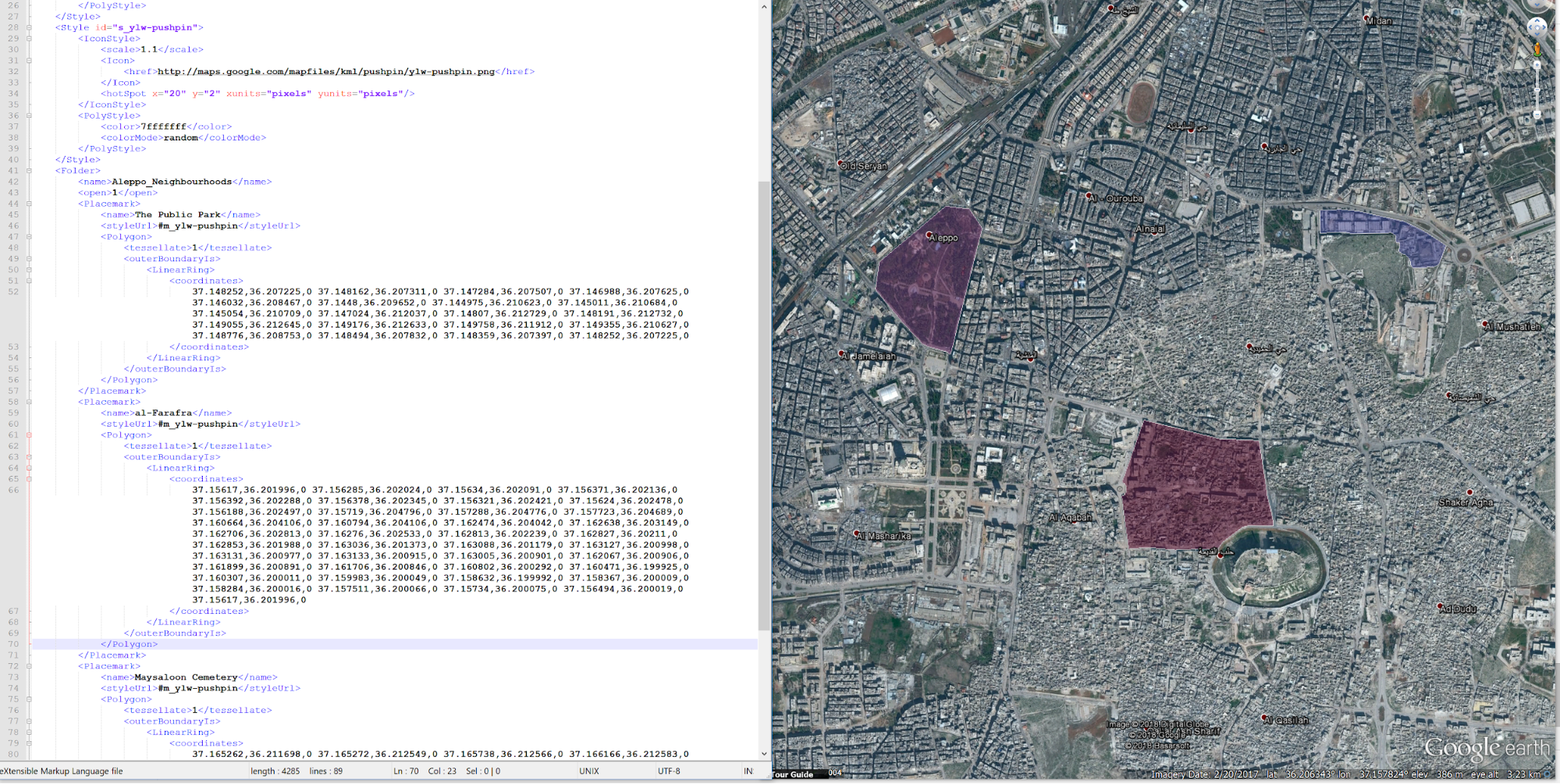
If you’re only looking to import a few features, it is easy to manually copy and paste entries into KML files, but if you are looking to import them all you need to reformat the whole data itself into a multi-featured KML file.
Replace “\n([A-Z|a-z])|\n|\1”, “([a-z])\n|\1\?\n”, “\n([0-9])|\n\!\1”, “([0-9])\n|\1#\n”.
These commands are to add markers to the start and end of each line so that in later commanders we can copy them into the XML format of the KML files. So that each two-line entry looks like this:

Now we have to use multi-line replace commands to add all entries into the KML , so it is probably easy to simply copy and paste what I’ve written out below, or to copy and paste the lines directly from a mock KML file you also have open.
- “\|| <Placemark>\n <name>”. This replaces any | character with the above string.
- “\?|</name>\n <styleUrl>#m_ylw-pushpin</styleUrl>\n <Polygon>\n <tessellate>1</tessellate>\n <outerBoundaryIs>\n <LinearRing>”. Likewise, this replaces the ? character with the above code, the following two commands do the same with ! and # characters.
- “\!| <coordinates>\n “
- “0\#|0\n </coordinates>\n </LinearRing>\n </outerBoundaryIs>\n </Polygon>\n </Placemark>\n”
- “</Placemark>\n\n <Placemark>|</Placemark>\n <Placemark>”. This command simply removes an empty line between XML codings.
In all of these, it is important to copy all the text, symbols and tabs between the | and the closing quotation mark.
Copy and paste the start and closing tags of the KML file, it is best to copy and paste them from a mock-up kml file, but they should look something like this:
<?xml version=”1.0″ encoding=”UTF-8″?>
<kml xmlns=”http://www.opengis.net/kml/2.2″ xmlns:gx=”http://www.google.com/kml/ext/2.2″ xmlns:kml=”http://www.opengis.net/kml/2.2″ xmlns:atom=”http://www.w3.org/2005/Atom”>
<Document>
<name>tmp.kml</name>
<StyleMap id=”m_ylw-pushpin”>
<Pair>
<key>normal</key>
<styleUrl>#s_ylw-pushpin</styleUrl>
</Pair>
<Pair>
<key>highlight</key>
<styleUrl>#s_ylw-pushpin_hl</styleUrl>
</Pair>
</StyleMap>
<Style id=”s_ylw-pushpin_hl”>
<IconStyle>
<scale>1.3</scale>
<Icon>
<href>http://maps.google.com/mapfiles/kml/pushpin/ylw-pushpin.png</href>
</Icon>
<hotSpot x=”20″ y=”2″ xunits=”pixels” yunits=”pixels”/>
</IconStyle>
<PolyStyle>
<color>7fffffff</color>
<colorMode>random</colorMode>
</PolyStyle>
</Style>
<Style id=”s_ylw-pushpin”>
<IconStyle>
<scale>1.1</scale>
<Icon>
<href>http://maps.google.com/mapfiles/kml/pushpin/ylw-pushpin.png</href>
</Icon>
<hotSpot x=”20″ y=”2″ xunits=”pixels” yunits=”pixels”/>
</IconStyle>
<PolyStyle>
<color>7fffffff</color>
<colorMode>random</colorMode>
</PolyStyle>
</Style>
<Folder>
<name>Aleppo_Neighbourhoods</name>
<open>1</open>
For the beginning, and..
</LinearRing>
</outerBoundaryIs>
</Polygon>
</Placemark>
</Folder>
</Document>
</kml>
…for the end.
Now try to save it as a KML (in the drop-down menu choose eXtensible Markup Language File and replace “xml” with “kml” in the save dialogue) and open it in Google Earth to look for any errors.
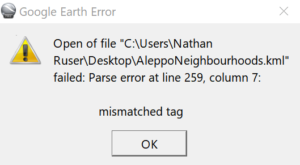
To diagnose we need to find line 259 and see what’s wrong. Here it’s easy to see:

In the find and replace tags, because the line ended in a “)” it didn’t receive the name end marker (“?”). Therefore, it is missing several lines of XML-coding between the <name> tag and the <coordinates> tag. The quickest way to fix this is to manually copy and paste the missing lines, but if your dataset has a lot of names that end in a closing bracket you can include that in the Find and Replace command used to add the name end marker, for example with the command “([a-z]|\))\n|\1\?\n”. My dataset had that same error for another 6 or 7 entries, but they were all fixed with a simple copy and paste of the missing lines.
And with that you have all the polygon entries in a single KML file that can be opened in Google Earth or imported into other GIS programs.
These are some examples of how to scrape public geospatial data for your own analysis. This can be used for most data-sets available in interactive maps. There are some exceptions, ArcGIS and QGIS’ native platforms hide their data through a Web Map Server, making it impossible to download the underlying data. Moreover, almost every dataset has its data organised in different ways. Hopefully, these basics can help you start to learn the skills you need to scrape data, but every dataset has its own challenges. Find your own favourite interactive map, and see what data you can extract from it.
If you want a true challenge, the most difficult dataset I have come across so far is an event database of crime information in the Philippines’ Autonomous Region in Muslim Mindanao (ARMM).
Regardless of what data you want to scrape and analyse, good luck, and it is also important that any derivative product you make from this data or analysis stemming from it is adequately attributed. Along with that, if you are to use the information for any commercial reasons it is important to get the explicit permission of the database curator to use their data.