
New Tools Dig Deeper Into Hard-to-Aggregate US Corporate Data
Do you want to unveil patterns in corporate behaviour, keep tabs on a company of interest, or gain access to free and accurate financial data for open source research? If so, you should consider using Electronic Data Gathering, Analysis, and Retrieval, or EDGAR.
This database of corporate and financial data maintained by the United States Securities and Exchange Commission (SEC) and accessible for free, contains millions of filings by public companies going back as far as 1994., And yet it remains underused by journalists, researchers, and financial analysts.
One reason it is underused is that many potential users are simply unaware of EDGAR and end up subscribing to one or more corporate data providers. Another is that they are all too familiar with EDGAR, namely the frustrating shortcomings of its interface:
- Users cannot download at once all the documents returned by a text search of the database
- Owing to shifting data tags, it’s extremely cumbersome to create financial profiles for single companies or to perform comparisons between their respective financial metrics
- There is no feature for subscribing to a single RSS feed of several companies that may interest you
To address these shortcomings, we have developed a suite of tools that we hope will encourage more people to use EDGAR for corporate and financial research. These tools allow users to programmatically save the results of search terms in EDGAR, create a financial profile of every company traded on a US exchange, and filter EDGAR’s broadest RSS feed by companies of interest.
Our goal was to make these resources accessible to as broad of an audience as possible and so, with the exception of our financial data tables, only basic knowledge of Python is required. You can access our tools here.
Search for Terms in the EDGAR Database and Programmatically Save the Results
The first of our tools makes it simple to record search results from EDGAR, surfacing data for free that others pay exorbitant amounts of money to get from third-party vendors.
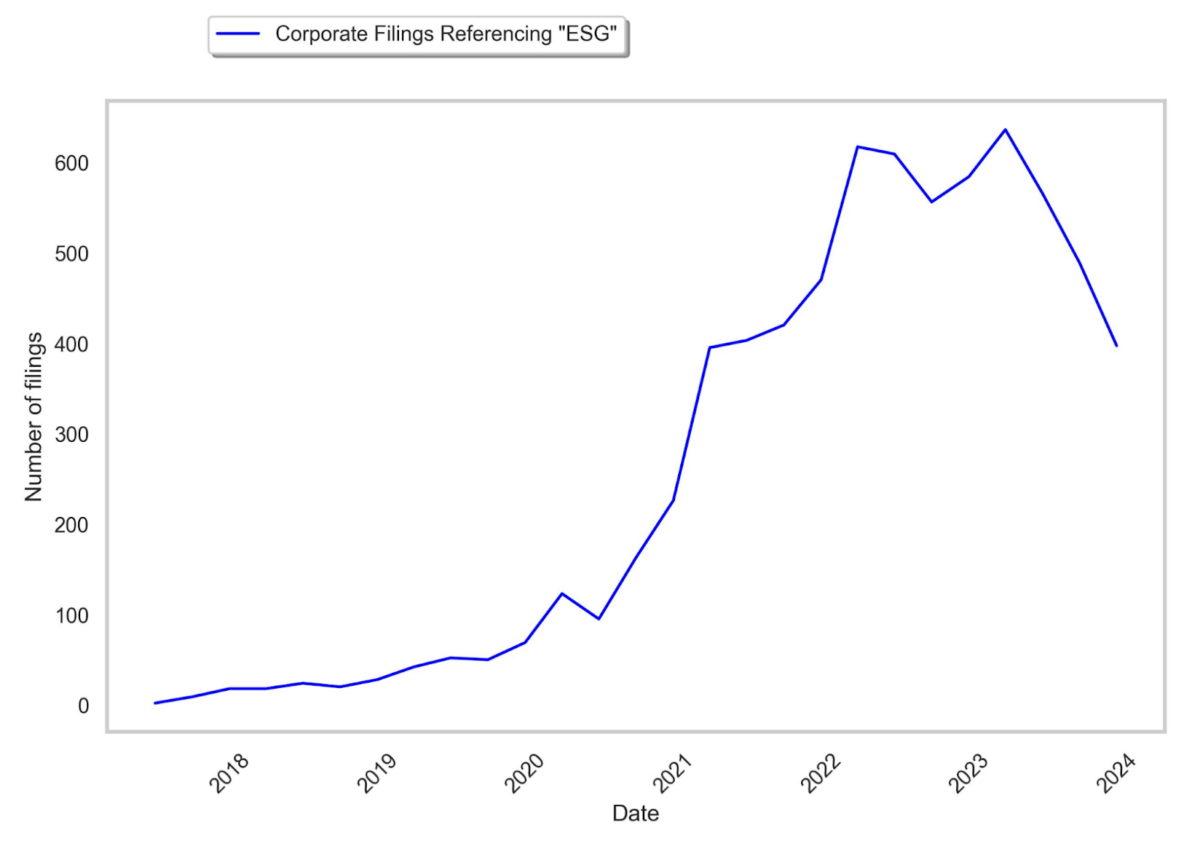
For example, a recurring theme in the Wall Street Journal is the declining importance of Environmental, Social, Governance (ESG) principles, as represented by the number of quarterly earnings calls in which company leadership addresses ESG issues. ESG encompasses investment strategies that touch on corporate social responsibility, and can include everything from investments in carbon offsets and green technology to strategies that avoid investing in supply chains with subpar labour standards. In June and September articles on the topic, the WSJ attributed data showing the decline in mentions of ESG to executives to AlphaSense and FactSet respectively. Both services’ subscriptions cost several thousand of dollars per year.
Fortunately, we can use the text search tool to show a similar ESG trend for free by searching for the term “ESG” within annual and quarterly reports filed with EDGAR:
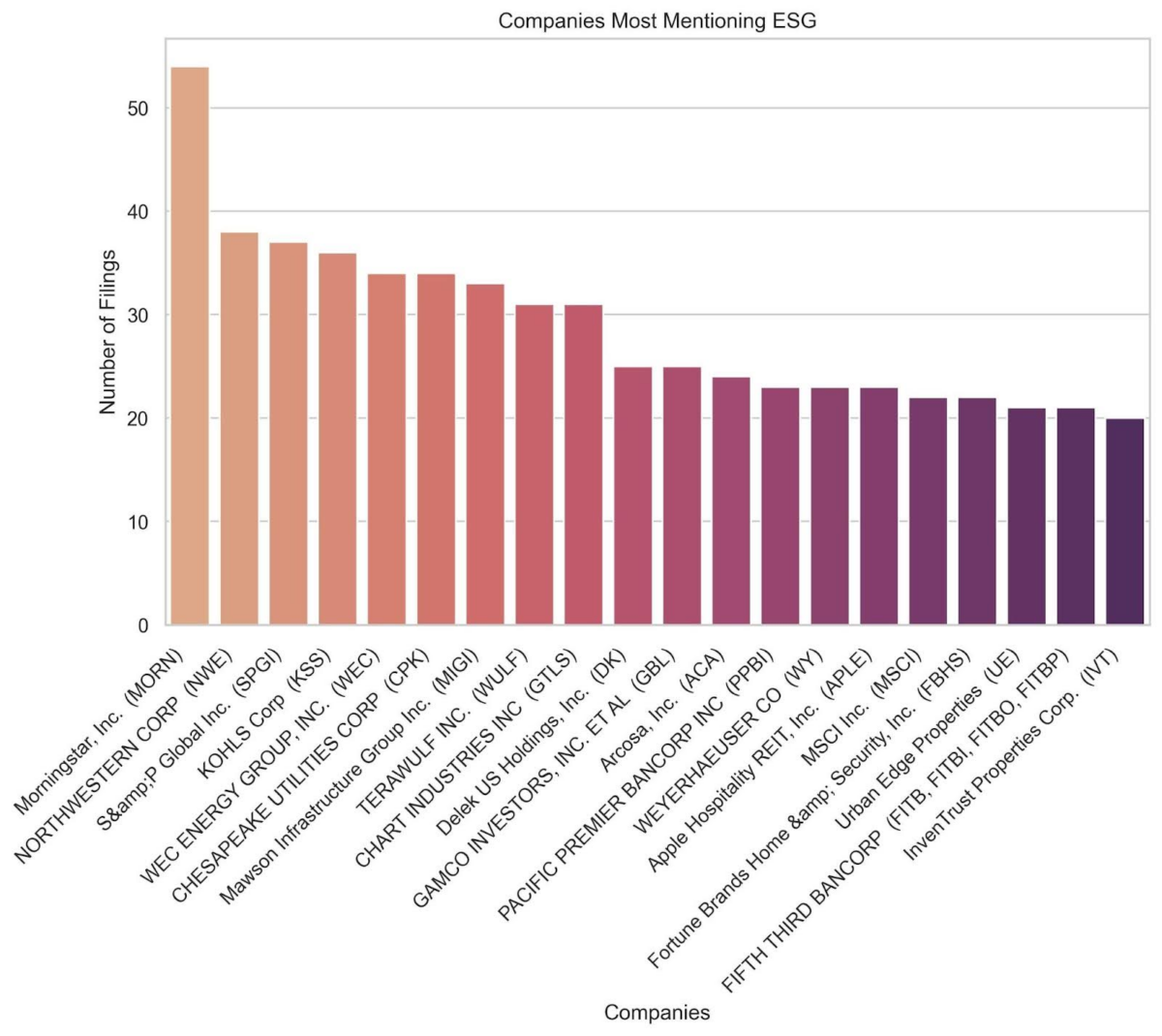
With this data, we can also highlight the companies that most frequently mention ESG:
The use of the EDGAR database to show broad trends across hundreds of thousands of filings is possible because our tool automatically breaks up the search into manageable chunks, crawls through each page of results, and appends the data into .csv format, which can be further exploited in Excel or, as in this instance, the Plotly library in Python.

Each result row in the returned .csv table includes the date, jurisdiction where the legal entity is registered, its principal place of business, its name, unique identifying number or Central Index Key (CIK), a URL for the filing index (which may include additional documents and information), and the link to the filing itself. As demonstrated with the ESG data, it sometimes isn’t even necessary to open the filings themselves to discover interesting patterns – the table data is sufficient.
Obtain a Full Financial Profile on Any Company Traded on a US Exchange
Our second tool lets users create a unique profile of any company that is traded on a US Exchange. On just the New York Stock Exchange and the Nasdaq Stock Market, there are over 2300 and 3600 listed companies, respectively.
Every company whose shares are available to the public must periodically report their financials to the SEC. This financial data is included within the text and .htm versions of the filings and is also stored in XBRL format, which uses a system of data tags, or taxonomies, to ensure that data points are consistent across time and across different companies.
For example, when a company tracks the number of outstanding shares it had during a reporting period, the text and tables of its report might use the terms “common shares,” “outstanding shares,” or “basic shares.” However, Within the XBRL document, a company’s number of outstanding shares might be associated with any of around a dozen tags chosen by their accountants.
These tags may change from year to year and from company to company, which makes EDGAR’s datasets of financial data of little use without processing. Through the study of taxonomy documents published by the XBRL foundation, a crash course in accounting, and the use of semantic and numeric matching, we were able to obtain a general schema for matching up a plain English term for around one hundred commonly used financial data points.

Using this term matching library as a reference, we created a single table of financial data covering all the companies that report to the SEC. We are continuously working to improve the table to address notable areas of improvement, including:
- Parsing data for non-US companies
- Handling missing data / typos in EDGAR data
- Lapses in the accuracy of the current parsing method
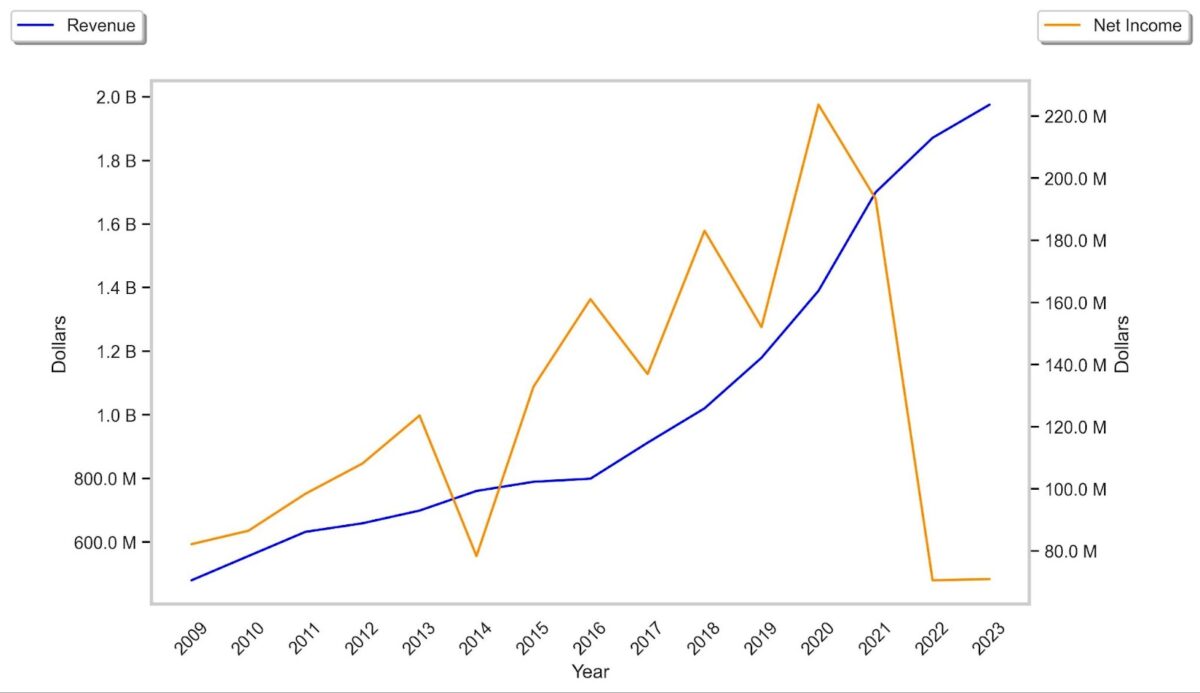
In its current form, the data set allows us to generate coherent and accurate data time series for most companies, and for most years. Here we see the declining net income (profit) of financial services firm Morningstar, which as we saw above, is one of the companies most associated with ESG investing:
RSS Feed Customisation
Our final tool lets users surface valuable information from EDGAR’s RSS feeds, which currently make it hard to track up-to-date information on individual companies.
EDGAR publishes several RSS feeds that provide a daily overview of new filings. While it is possible to subscribe to individual company feeds, following several companies through multiple subscriptions is burdensome.
We find it more practical to access one of the main RSS feeds and then filter the results by companies of interest.
To this end, we’ve built a simple tool that allows the user to input a list of stocks of interest, and then send a request to EDGAR’s broadest RSS feed, including both XBRL and non-XBRL filings. The tool returns a CSV file in a format similar to the text search tool, with entity date, entity name, ticker, filing type, CIK number, and links to the filing and its index.
As with the text search tool, the RSS tool is useful for research queries with either narrow or wide focuses. For example, we can keep tabs on a group of companies of interest, or alternatively, we can use the unfiltered daily results to keep a finger on the pulse of the broader market. One particularly fruitful use case is to feed all of the daily filings into a LLM to produce and store concise summaries of the filing texts.
A Final Note
These tools are a work in progress and may need to be adapted to potential changes in the scope and format of EDGAR. Additionally, we hope to adapt and expand upon this toolset in response to your feedback and suggested use cases. Please reach out to either Bellingcat or fellow George Dyer of Market Inference with your comments and questions, and we will gladly assist you.
Our goal is to ensure that the EDGAR database is being used to its fullest extent by the widest possible group of people.
Bellingcat is a non-profit and the ability to carry out our work is dependent on the kind support of individual donors. If you would like to support our work, you can do so here. You can also subscribe to our Patreon channel here. Subscribe to our Newsletter and follow us on Instagram here, X here and Mastodon here.

