
Using Python to Mine Common Crawl
Translations:
This article was originally posted on the AutomatingOSINT.com blog.
One of my Automating OSINT students Michael Rossi (@RossiMI01) pinged me with an interesting challenge. He had mentioned that the Common Crawl project is an excellent source of OSINT, as you can begin to explore any page snapshots they have stored for a target domain. Michael wanted to take this a step further and mine out all external links from the returned HTML. This can enable you to find relationships between one domain and another, and of course potentially discover links to social media accounts or other websites that might be of interest. This blog post walks you through how to approach this problem so that you can automate the retrieval of external links from a target domain that has been stored in Common Crawl. Here we go!
What is Common Crawl?
Common Crawl is a gigantic dataset that is created by crawling the web. They provide the data in both downloadable format (gigantic) or you can query against their indices and only retrieve back the information you are after. It is also 100% free, which makes it even more awesome.
They provide an API that will allow you to query a particular index (indexes are snapshots for each crawling run they perform) for a particular domain, and it will return back results that point you to the location of where the actual HTML content for that snapshot lives. The API documentation can be found here.
Once the API returns back the results you are looking for, you need to then reach into the compressed archive files stored on Amazon S3 and pull out the actual content. This is where Stephen Merity (@smerity) came to my rescue. He posted some example code here that demonstrated how to retrieve items from the archived files on S3. Beauty, let’s get started.
Coding It Up
First off you need to install a couple of Python modules (if you don’t know how to do that check out my tutorials here):
pip install requests bs4
Now let’s crack open a new file and call it commoncrawler.py and punch out the following code (you can download the source here):
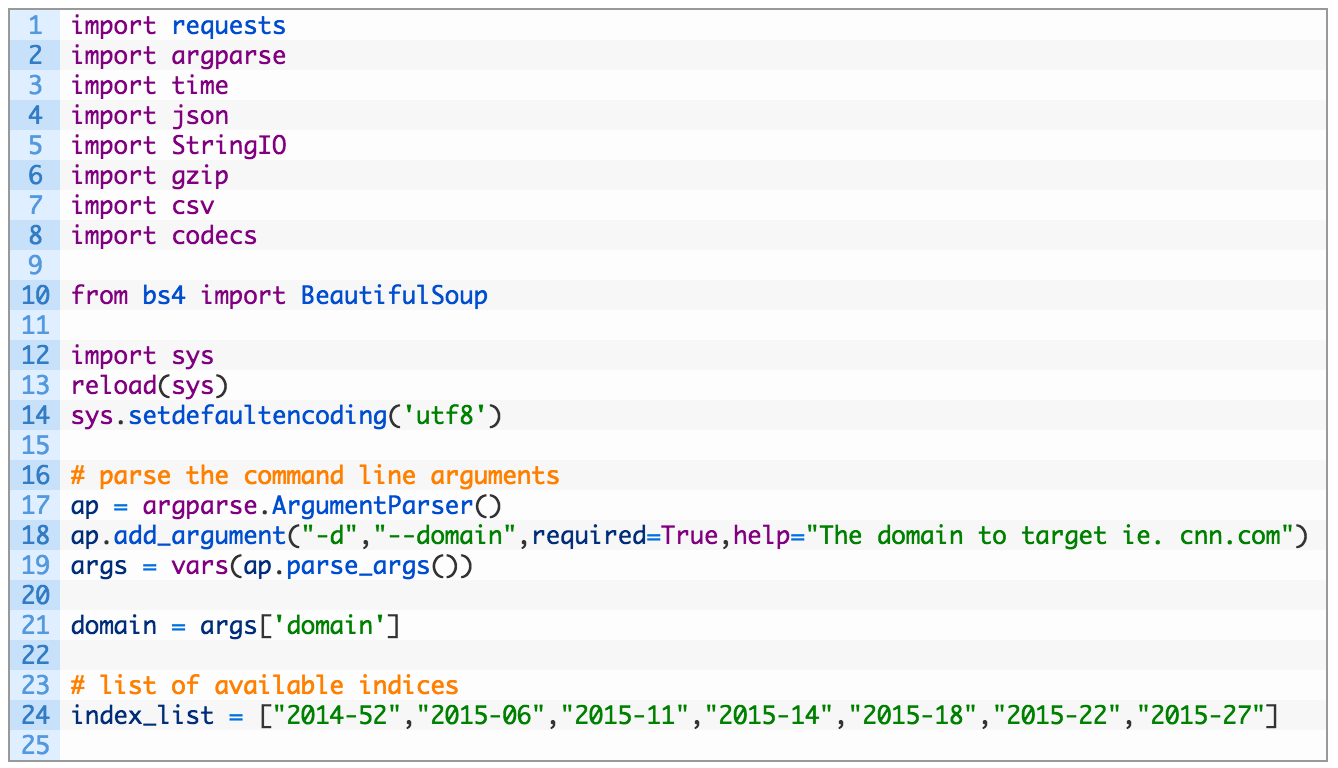
Let’s look at what this first bit of code does:
- Lines 12-14: this is a hack to force the use of UTF-8 character encoding to keep the csv module happy when we are outputting results to our spreadsheet.
- Lines 16-21: here we are just parsing out our command line arguments and storing the result in our domain variable.
- Line 24: this is a list of all of the Common Crawl indices that we can query for snapshots of the target domain.
Alright now let’s put the function in that will deal with making queries to the Common Crawl API and handling the results. Add the following code to your script:
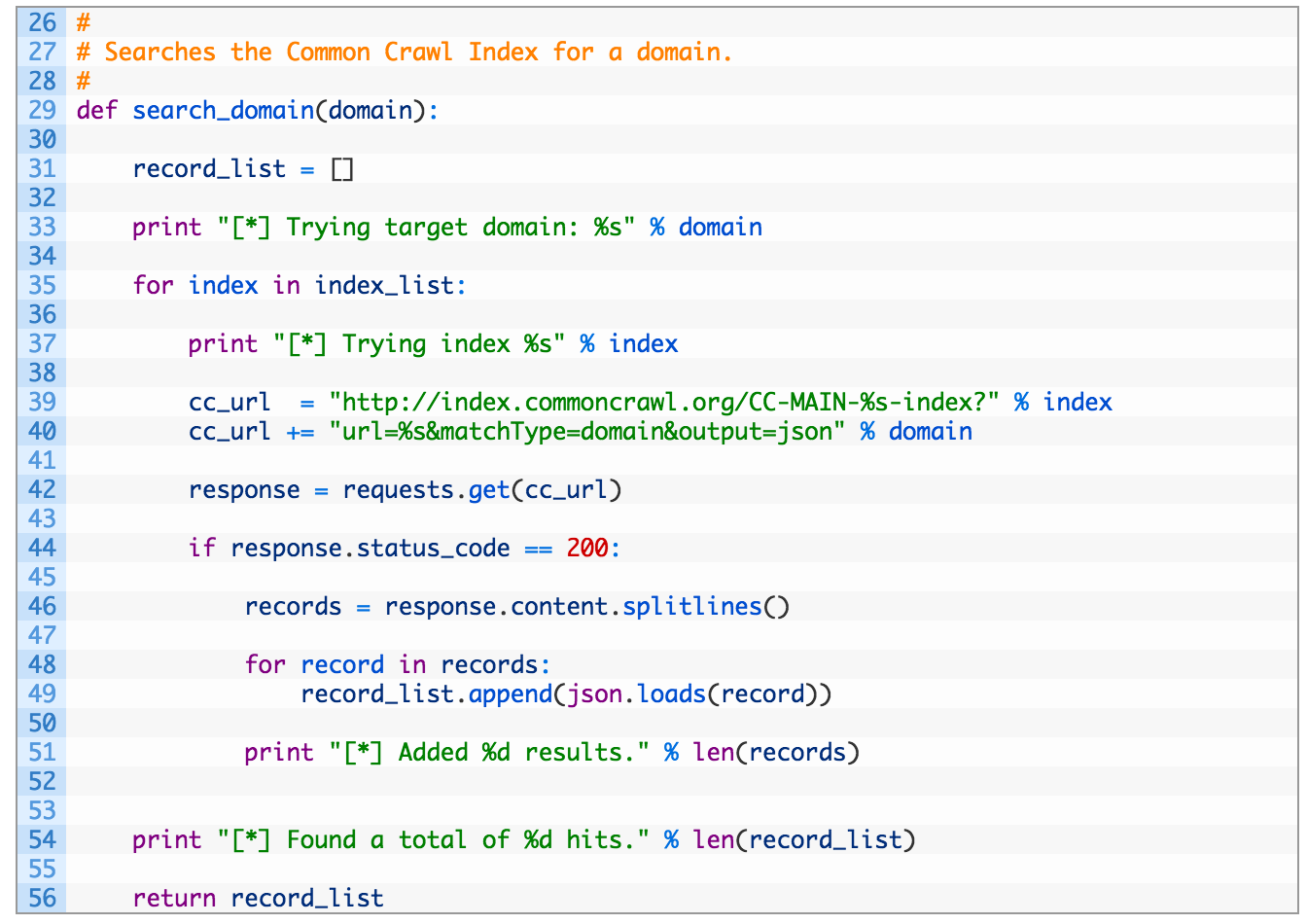
Ok so our searching function is complete, let’s look at the important parts:
- Lines 35-40: here we are iterating over the available indices (35) and then building a search URL (39-40) that we’ll hit to retrieve the results.
- Lines 46-51: as the response is multiple chunks of JSON data, we have to split the lines (46), and then parse each line (48,49). We finish by printing out a friendly message to let us know if we had any hits (51).
When the function is finished it returns our full list of results that we can then use to retrieve the actual data from the index. Let’s implement that function now:

This is borrowed heavily from Stephen’s code (thanks again Stephen). Let’s take a look at what he’s doing here:
- Lines 64-65: we use two of the keys from our record variable that contains the offset and the length of the data stored in the compressed archive.
- Lines 69-72: we build up a URL to Amazon’s S3 and utilize a HTTP range request to request the specific byte offset and length of the result in the compressed archive. This saves you from having to download then entire compressed file, brilliant move by Stephen again.
- Lines 76-80: here we use the StringIO module to get a file-like descriptor to the returned data (76) which we pass along to the gzip module (77) to decompress the data. Once the data is decompressed we read it out into our data variable (80).
- Lines 82-90: now we split the data into three parts: the warc variable holds the metadata for the page in the WARC archive, the header variable has the HTTP headers retrieved when Common Crawl hit the target domain and the response variable contains the body of the HTML we want. If all is well we return the HTML data.
Now that we can search for a domain and extract the raw HTML from the Common Crawl indices, we need to extract all of the links. Let’s implement a function that will do just that:
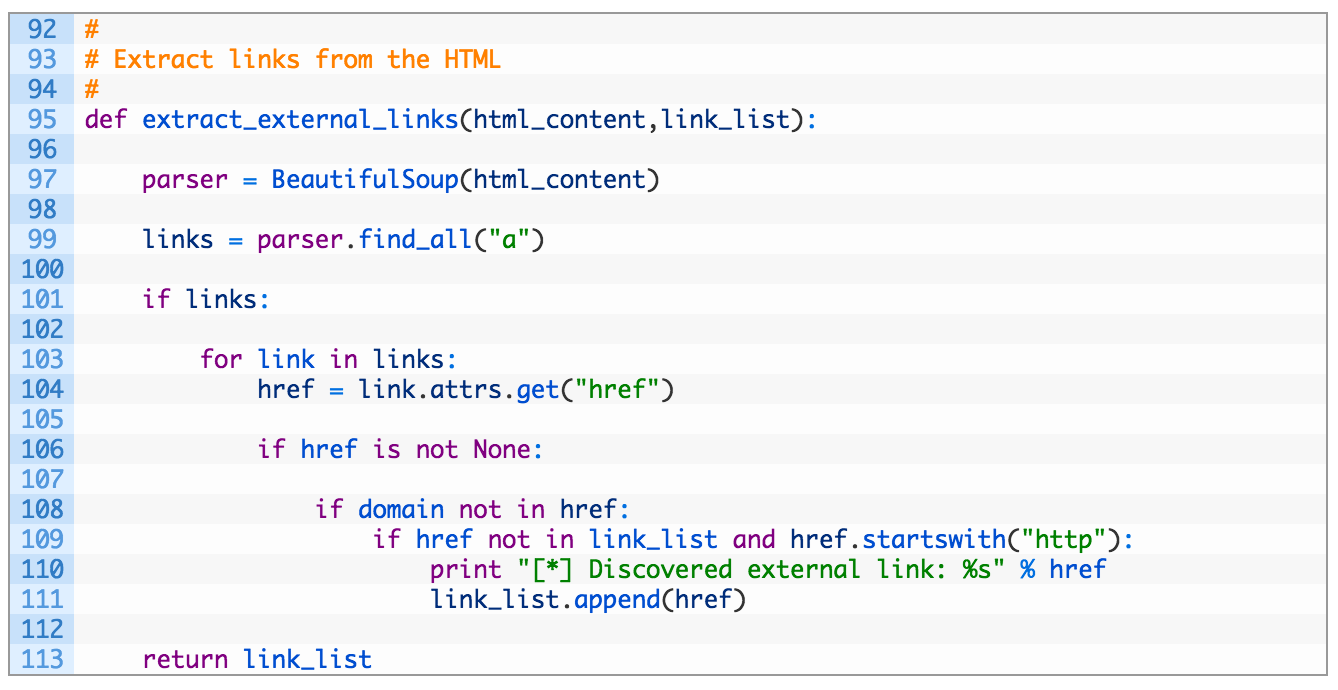
Let’s have a peek at what this code does. We’re nearly there!
- Line 95: we construct our function to retrieve the raw HTML and a list of links. The list of links will ensure that we aren’t storing duplicates of the same link, although if you wanted to use some visualization you could keep this in place and measure the weight of how commonly some sites are connected to your target domain. I’ll leave that to you for homework.
- Lines 97-99: we pass the raw HTML content to BeautifulSoup (97) and then we ask it to parse out all of the links (99).
- Lines 103-111: now we iterate over the list of links (103) and pull out the href attribute (104). If the target domain is not in the link and it’s not already in our list of links we add it to our master link list and carry on.
Ok our main functions are in place, and now we can put the final code in place to actually run our functions and log the results.
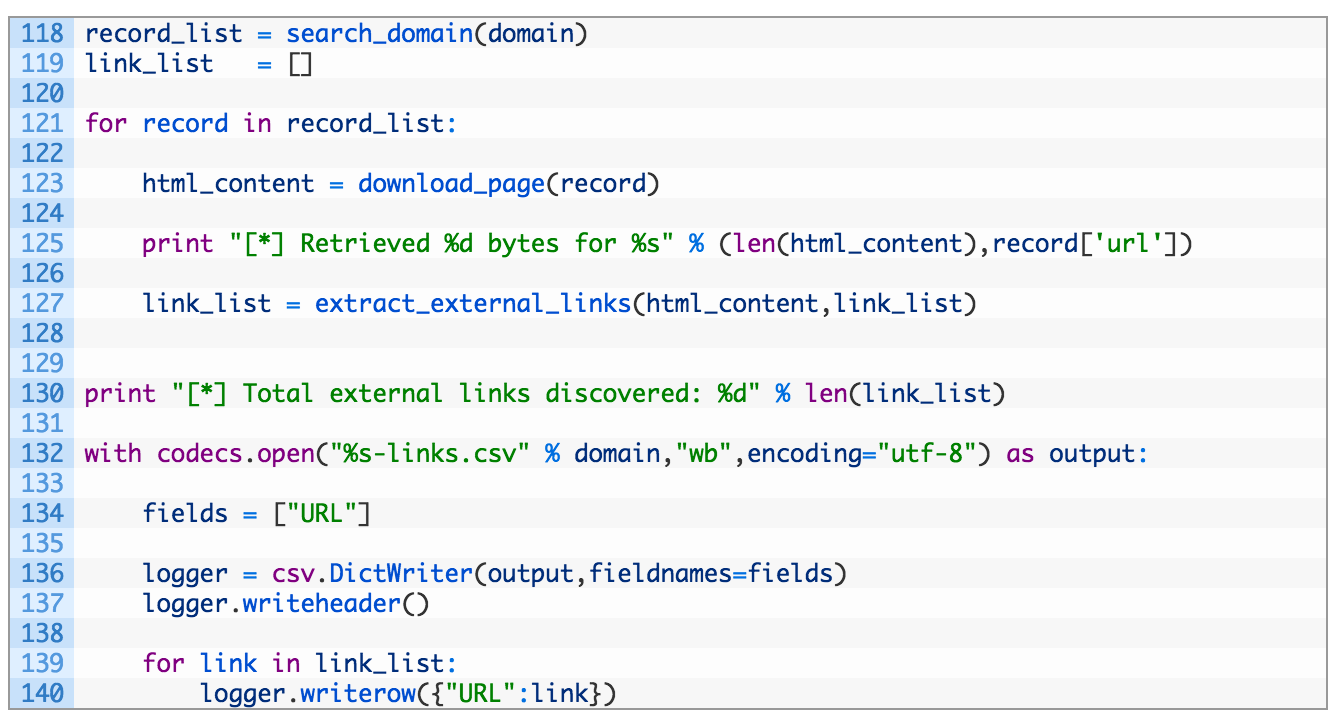
Alright, this is the last of it, let’s review:
- Line 118: we call our search_domain function to retrieve search results from Common Crawl.
- Lines 121-127: we iterate over our search results (121), pull down the raw HTML (123) and then extract the list of links from the page (127).
- Lines 132-140: we crack open a new CSV file named using our target domain (132) and then set a single column name for our spreadsheet (134). We initialize the DictWriter class with our logfile descriptor and column name (136) and then write out the header row in the CSV (137). Then we simple iterate over the list of links (139) and add each URL to our CSV (140).
Whew! Now of course you could capture other metadata from the search results (such as the timestamp) to store alongside each URL if you like, or you could make this whole operation recursive by then attempting to try each additional domain you have discovered for links that they link to. Really, the world is your OSINT oyster at this point. Let’s take it for a spin.
Let it Rip
You can run this from inside Wing (or other Python IDE) or from the command line like so:
C:\Python27\> python commoncrawler.py -d bellingcat.com
[*] Trying target domain: bellingcat.com
[*] Trying index 2014-52
[*] Trying index 2015-06
[*] Trying index 2015-11
[*] Added 7 results.
[*] Trying index 2015-14
[*] Added 7 results.
[*] Trying index 2015-18
[*] Added 7 results.
[*] Trying index 2015-22
[*] Added 7 results.
[*] Trying index 2015-27
[*] Added 6 results.
[*] Found a total of 34 hits.
[*] Retrieved 49622 bytes for https://www.bellingcat.com/
[*] Discovered external link: http://www.twitter.com/bellingcat
[*] Retrieved 49622 bytes for https://www.bellingcat.com/
[*] Retrieved 61330 bytes for https://www.bellingcat.com/news/uk-and-europe/2014/07/22/evidence-that-russian-claims-about-the-mh17-buk-missile-launcher-are-false/
[*] Discovered external link: https://www.youtube.com/watch?v=4bNPInuSqfs#t=1567
[*] Discovered external link: http://rt.com/news/174496-malaysia-crash-russia-questions/
<SNIP>
[*] Total external links discovered: 67
Cool, we discovered 67 external domains that Bellingcat links to. Not bad! If you check the same directory as your script you will see a CSV file that has all of the external URLs stored that you can then feed into your own crawler or manually investigate. Of course you could use some text processing on the external pages as well.
